Rust:为什么不能在同一个结构体中存储一个值和对该值的引用?
基本把下面问题这个搞明白,就能彻底明白 Rust 语言的生命周期是怎么回事了。简而言之,生命周期不会改变你的代码,是你的生命控制生命周期,而不是生命周期在控制你的代码。换言之,生命周期是描述性的,而不是规定性的。
原文:https://stackoverflow.com/questions/32300132/why-cant-i-store-a-value-and-a-reference-to-that-value-in-the-same-struct,作者:kmdreko
[TOC]
问题
能否在同一个结构体中,同时存储一个值和对该值的引用?
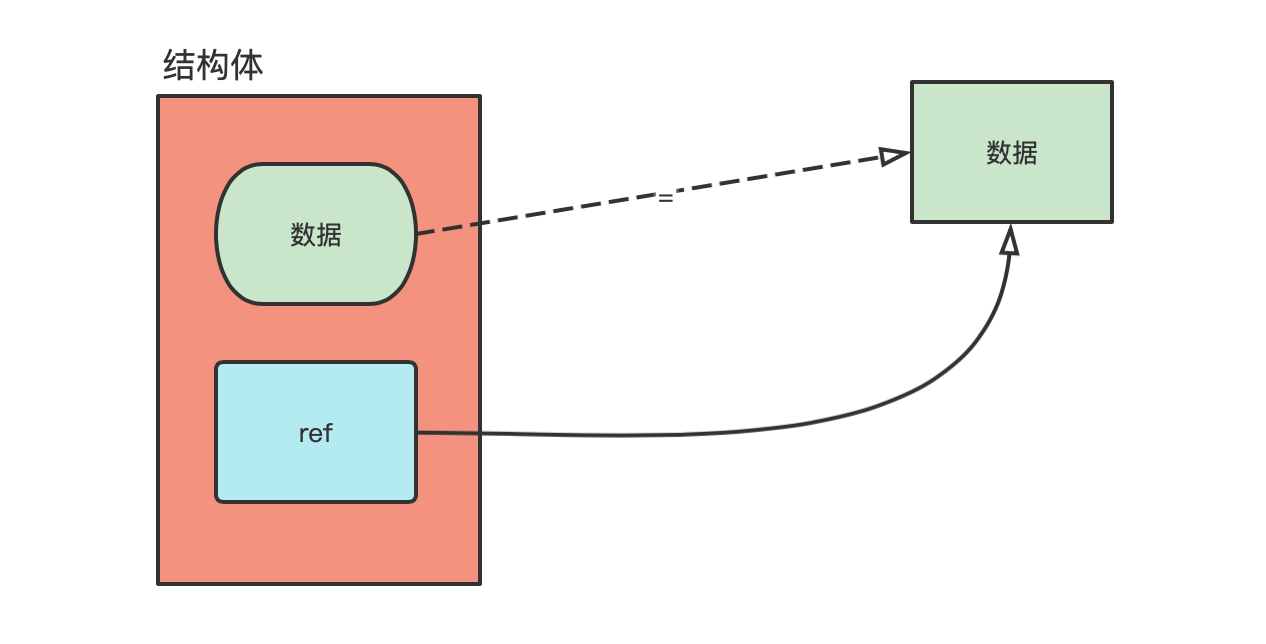
这个问题很有意思,在一个含有自动 GC(垃圾回收)功能的编程语言里,在一个数据结构内同时存储一块数据及该数据的引用,这是非常容易的事,举个例子:
// JS
let data = ["a", "b", "c"]
let obj = {data, ref: data}
console.assert(obj.data[0] === obj.ref["0"]) // 断言正常,值均是'a'
这是一个 JS 语言示例,这个例子很简单,obj.data[0]与 obj.ref["0"]虽然访问方法不同,但异曲同工,指向了同一块内存地址。obj.data 是一块数据,obj.ref 是指向这块数据的引用。
C 语言示例
由于 JS 中没有指针,演示这个问题可能不是很合适,下面我们看另一个 C 语言示例:
#include <stdio.h>
int main()
{
struct
{
char data[3];
char *ref;
} obj = {{'a','b','c'}};
obj.ref = obj.data;
printf("%s = %s\n", obj.data, obj.ref);// Output:abc = abc
return 0;
}
在这个示例中,obj.data 是一个字符数组,obj.ref 是指向这块字符数组数据的指针,它们同时位于一个结构体内,满足了问题假设。
==将一个值,和对该值的引用,同时存储于一个结构体内,这在 C、C++等可操作指针的编程语言中没有任何问题。==
然而,这在 Rust 中却成了问题。
Rust 问题示例
看示例代码 1:
struct Thing {
count: u32,
}
struct Combined<'a>(Thing, &'a u32);
fn make_combined<'a>() -> Combined<'a> {
let thing = Thing { count: 42 };
Combined(thing, &thing.count)
}
第 5 行,这是一个元组结构体,它有两个成员,第一个是 Thing 类型,第二个是 u32 类型。代码的本意是,在 Combined 结构体内,同时存储数据 Thing,及指向该 Thing 实例中 u32 真实数据的指针(Thing 类型中的 count 是 u32 类型)。
编译这段代码,不出意外的话,会得到两个编译错误:
error[E0515]: cannot return value referencing local data `thing.count`
error[E0382]: borrow of moved value: `thing`
**为什么会报错?**你先想一下。
下面接着再看第二个代码示例 2:
struct Thing {
count: u32,
}
impl Thing {
fn new() -> Thing {
Thing { count: 0 }
}
}
struct Combined<'a>(Thing, &'a Thing);
fn make_combined<'a>() -> Combined<'a> {
let thing = Thing::new();
// error[E0515]: cannot return value referencing local variable `thing`
// error[E0382]: borrow of moved value: `thing`
Combined(thing, &thing)
}
fn main() {
make_combined();
}
在该示例中,我们的要求退化了,不再存储数据的指针,改为存储数据实例对象的引用。第 11 行,在结构体 Combined 中,Thing 是数据结构体,&'a Thing 是结构体实例的引用。
但这样仍然不可以,它在编译时得到了两条同样的编译错误:
error[E0515]: cannot return value referencing local variable `thing`
error[E0382]: borrow of moved value: `thing`
Rust 错误都有唯一的错误 ID,只要方括号内以 E 开头的错误 ID 一致,错误便是一样的。
这个问题是由一位提问者提出者,他还贴了第三段代码,下面看第三个代码示例 3:
struct Combined<'a>(Parent, Child<'a>);
fn make_combined<'a>() -> Combined<'a> {
let parent = Parent::new();
let child = parent.child();
Combined(parent, child)
}
在这个示例中,提问者不试图在 Combined 中存储任何指针或引用了,但仍然得到了同样的错误。问为什么?
下在是来自 kmdreko 的回答。
引起错误的背后语法原理
让我们先看一个简单的实现:
struct Parent {
count: u32,
}
struct Child<'a> {
parent: &'a Parent,
}
struct Combined<'a> {
parent: Parent,
child: Child<'a>,
}
impl<'a> Combined<'a> {
fn new() -> Self {
let parent = Parent { count: 42 };
let child = Child { parent: &parent };
Combined { parent, child }
}
}
fn main() {}
该示例将编译失败,并主要展示如下错误:
error[E0515]: cannot return value referencing local variable `parent`
error[E0505]: cannot move out of `parent` because it is borrowed
要理解这些错误,你必须思考这些值(例如 parent)在内存是如何展示的,以及当我们移动它们时又发生了什么。如下所示,我们假设这些值的内存地址是这样的,我们以此注释我们的 Combined::new 代码,看看这里面内存发生了什么变化:
// 下面假设Parent与Child均没有实现Copy主义,它们将发生Move移动
let parent = Parent { count: 42 }; // 0x1000
// `parent`变量初始位于内存地址0x1000处
// `parent`的真实值是42
let child = Child { parent: &parent }; // 0x1010
// `child`变量位于内存地址0x1010处,注意它的地址与parent不同
// `child`的真实值是一个地址,是0x1000
Combined { parent, child } // 0x2000
// 返回值的内存地址位于0x2000处
// 现在`parent`被移到了内存地址0x2000这个地方
// 那么此时`child`的内存地址是什么 ?
对于 child 这个变量,它发生了什么?开始它位于 0x1010 这个地址,它的数据指向 0x1000 这个地址,但是在最后当返回值发生返回时,即在 parent 发生了移动以后,child 变量所指向的内存地址已经不能保证含有正确的值了。任何其它代码都将被允许在内存地址 0x1000 存储新值,这时候如果假想原来那块内存地址(0x1000)仍然是整型数字并勇敢地访问它,将引发崩溃或安全 Bug,这是 Rust 禁止的主要错误类别之一。
这个问题正是生命周期(lifetimes)要解决的问题。**生命周期是一个充许你和编译器知道,一个值在它当前的内存存储序列里( current memory location)能够存活多久的一个元数据信息。**这里有一点特别重要,Rust 新手经常在这里犯错误。要注意,Rust 的生命周期并不是简单的指在一个对象被创建和被销毁之间的时间周期。
注:上面这一段不是很好理解,大概意思是讲,生命周期并不是简单的可以理解为,是在变量被创建和被销毁之间的这段时间。有时候从代码上看,一个变量应该被销毁(结束)了,但其实它的生命周期仍然有效。例如'static 生命周期,它是贯穿整个应用程序运行时的。
打个比方,我们可以这样想:在人们的一生中,他们会在许多不同的地方驻足,每一个地方都是一个完全不同的地址。想象你是代码中的一个变量,Rust 的生命周期只会关心你当前在哪一个地址,而不会关心将来你在什么地方什么时候会死(尽管死亡也会改变你驻足的地址)。每一次你搬家都意味着你的地址不再有效。
有一点非常重要:生命周期不会改变你的代码,是你的生命控制生命周期,而不是生命周期在控制你的代码。换言之,生命周期是描述性的,而不是规定性的。
下面我们用一组行号数字,标注一下 Combined::new 代码,稍后这些行号将帮助我们更好地理解生命周期:
{ // 0
let parent = Parent { count: 42 }; // 1
let child = Child { parent: &parent }; // 2
// 3
Combined { parent, child } // 4
} // 5
parent 变量的实际生命周期是 1 至 4,包含 1 和 4,用数学集合符号表示是[1,4]。child 变量的实际生命周期是[2,4],返回值的实际生命周期是[4,5]。这里也有可能存在一个从 0 开始的生命周期,它代表整个代码块之外的某个函数参数或其它什么的生命周期,这不重要,我们现在可以不管它。
请注意,child 的生命周期是[2,4],但是它指向了生命周期是[1,4]的值(即 parent)。一般只要引用值(child)在被引用值(parent)变成生命周期无效之前变成无效,就没事。(作者注:换言之,引用值的生命周期总是会小于被引用值的生命周期长度的。)编译错误发生在当我们想从代码块返回 child 变量时,这会撑爆生命周期的自然长度。
到这里为止,以上内容可以解释前两个不工作的示例代码了。第三个示例还要看一下 Parent::child 代码的实现,它包含的变化如下所示:
impl Parent {
fn child(&self) -> Child { /* ... */ }
}
这段代码自动应用了生命周期省略(lifetime elision,Rust 的语法特性),从而避免了严格的一般的生命周期参数标注的繁琐劳动。上面的代码实际等同于下面这个非省略版本:
impl Parent {
fn child<'a>(&'a self) -> Child<'a> { /* ... */ }
}
(注:这里只有 self 一个参数,根据省略三原则,因为 Rust 编译器可以推断出正确的生命周期标注,所以编译器就帮助开发者省略了。)
对于这段代码,可以分两种方式解释:一种解释是,child 方法表明它会返回一个由 self 参数的实际生命周期参数化的 Child 结构体实例;另一种解释是,Child 实例包含一个创建它的 Parent 实例的引用(该引用指向 Child 实例外部一个拥有更大生命周期的实倒),Child 实例不能比 Parent 实例存活的周期长。
这让我们意识到,我们(提问者)的创建代码:
fn make_combined<'a>() -> Combined<'a> { /* ... */ }
有时候你更有可能看到下面这种另一种形式的不同写法(作用相同):
impl<'a> Combined<'a> {
fn new() -> Combined<'a> { /* ... */ }
}
在这两种写法下,没有生命周期参数作为参数提供了,这意味着 Combined 类型将不受来自调用者的任何约束。这太荒谬了,调用者只能适配'static 静态全局生命周期,这根本无法满足它的调用条件。
怎么解决此类问题?
最简单的解决方案是不将数据和引用放在同一个结构体中。为此,可以使用嵌套的结构体模拟代码的生命周期。将包含自身数据的类型一起放在结构体中,如有必要,提供访问引用或包含引用的对象的方法。
有一种特别情况,当把一些数据放在堆上的时候,生命周期会超出预想范围。举个例子,在使用Box<T>的情况下,结构体会变成一个包含指向堆上数据指针的容器,指针指向的数据会保持稳定,但是指针本身的地址却会变化。在实践中,这其实没有关系,因为作为开发者的你可以追随指针编程。
翻译结束,以下是作者的补充内容。
如何返回局部变量?
在 Rust 中,对于如何返回局部变量,有人总结了以下三种方法:
Box<T> instead of &T
Vec<T> instead of &[T]
String instead of &str
稍微解释一下,遇到&T 类型用Box<T>类型返回。后面类似。
第 1 个出错示例改写(有修改)
对于出错的示例代码 1,可以这样改写:
struct Thing {
count: u32,
}
struct Combined<'a>(&'a Thing, &'a u32);
fn make_combined<'a>() -> Combined<'a> {
let thing = &Thing { count: 42 };
// error[E0515]: cannot return value referencing local data `thing.count`
// error[E0382]: borrow of moved value: `thing`
Combined(thing, &thing.count)
}
fn main() {
make_combined();
}
改动只有两处:
- 第 5 行,将第一个元组类型 Ting,修改为了&'a Thing,由值类型改用了引用类型;
- 第 8 行,在实例前加了&符号,代表取引用。
然后,代码就编译通过了!
==为什么这样就可以了?==
感谢几位知友指出问题,上面的描述是不恰当的。关于堆栈内存的分配,摘录一段选自《The Rust Programming Language》的文字:
All values in Rust are stack allocated by default. Values can be boxed (allocated on the heap) by creating a Box<T>. A box is a smart pointer to a heap allocated value of type T.
这段话的大概意思是说:因为栈处理比较快,在 Rust 中,所有值默认都会被分配到栈上。通过创建一个 Box<T>容器,值可以被装箱,将原本应该分配在栈上的值分配到堆上。
对于下面这个结构体:
struct Thing {
count: u32,
}
它的域是原生类型,结构体大小是固定的,它会优先被分配在栈上。除非如前面所讲,我们使用Box<T>或其它方法将实例装箱,这样才会被分配在堆上。
如果使用宏属性实现了 Copy trait(默认是非实现的),如下所示,这只是会让 Move 不再发生,对堆栈内存分配还没有足够的证据表明它们之间是有联系的。并不能说没有实现 Copy trait 就一定会被分配在堆上,这是不恰当的,如果真真是这样,前面原作者 kmdreko 所举的包含内存地址变化的第二个示例就可能不成立了。
#[derive(Copy,Clone)]
struct Thing {
count: u32,
}
其实很简单,规则只有一条,凡是能在编译期确定大小的类型,默认都是分配在栈上的;不能确定大小的类型,也无法在编译器分配在栈上,只能分配在堆上。
这段话也容易产生歧义,换一个说法:理论上编译期可以确定大小的值,都会被放在栈上,包括 Rust 提供的原生类型(例如字符、数组、元组(tuple)等),以及开发者自定义的固定大小的结构体(struct)、枚举(enum)等类型。
这一段描述很不恰当。在 Rust 中,并非只有堆、栈内存,还有全局内存区(包括静态变量区和字面量区),Rust 编译器会将全局内存区的数据直接嵌入在二进制程序文件中,像代码中的字符串字面量、static 关键字定义的静态变量都会被硬编码到全局内存区,对于这个全局内存区的变量,我们可以将它们的生命周期视为'static 全局生命周期。
上面改写后的示例,之所以可以运行,也是因为 thing 变量处在全局内存区,如下所示,第 8 行,我们给 thing 变量添加一个'static 的生命周期标注,代码仍然可以正常运行:
struct Thing {
count: u32,
}
struct Combined<'a>(&'a Thing, &'a u32);
fn make_combined<'a>() -> Combined<'a> {
let thing:&'static Thing = &Thing { count: 42 };
Combined(thing, &thing.count)
}
fn main() {
make_combined();
}
至于前面我们改写示例 1 的第 5 行,修改元组类型及生命周期标注,只是配合第 8 行而做出的改变。这里的生命周期标注,其实不一定非得是'a,它也可以是'static:
struct Combined<'a>(&'static Thing, &'a u32);
为什么可以是'static,因为它本来就是'static。
问题研究到这里,有人可能会想:我们能不能给函数 make_combined 传个参数,不要把 count 写死,看一个示例:
struct Thing {
count: u32,
}
struct Combined<'a>(&'a Thing, &'a u32);
fn make_combined<'a>(count:u32) -> Combined<'a> {
let thing = &Thing { count }; // 这里的count是传入的
Combined(thing, &thing.count)
}
fn main() {
make_combined(42 as u32);
}
这样就不能行了,会报 E0515 的 Error:
error[E0515]: cannot return value referencing temporary value
为什么?为什么不传值就可以,传值就不可以了?
Rust 中的函数存于全局的函数调用栈中,如果我们不传递参数,原来生成 thing 变量的代码,是不因外部条件而改变的,Rust 编译器可以将它视为函数体静态代码的一部分,可以将其放在全局内存区。
但有了条件以后,这个条件是运行时收入的,就不能这样操作了。
这个时候,可能有人会想,如果我们给 thing 变量强加一个'static 生命周期标注呢?如下所示:
struct Thing {
count: u32,
}
struct Combined<'a>(&'a Thing, &'a u32);
fn make_combined<'a>(count:u32) -> Combined<'a> {
let thing:&'static Thing = &Thing { count };
Combined(thing, &thing.count)
}
fn main() {
make_combined(42 as u32);
}
这样也不好使,会报 E0716 的 Error。想想前面原作者 kmdreko 讲过:生命周期不能控制代码,生命周期反而是被代码控制的,生命周期标注它是描述性的,而非规定性的。
前面我们可以给 thing 添加'static 标注,那是因为它本身就在全局内存区;现在不能加,是因为它受外参的影响,已经不在全局内存区了。
那么,难道我们就不能在函数有参数的前提下,把示例改好吗?当然不是,看这个示例:
#[derive(Debug,Copy,Clone)]
struct Thing {
count: u32,
}
impl Thing {
fn new(count:u32) -> Self {
Self{count}
}
}
struct Combined<'a>(Thing, &'a u32);
fn make_combined<'a>(count:&'a u32) -> Combined<'a> {
let thing = Thing::new(*count); // 可以
Combined(thing, count)
}
fn main() {
let a = Thing::new(32 as u32);
println!("{:?}", a);
make_combined(&(42 as u32));
}
它就可以运行,没有问题!
同时它也满足了提问者的要求,我们在 Combined 结构体中,存储了数据(Thing 类型),及针对真实数据的引用(u32 类型),在第 12 行。
在这个示例中,第 14 行,我们将 count 以不可变引用的方式传入,它是 make_combined 函数的唯一条件,它的生命周期是'a(有标注),与变量 thing 具有同样的生命周期(在 make_combined 函数上有标注)。
回想前面在问答中,关于生命周期原作者 kmdreko 讲过,只要引用值的生命周期比被引用值的生命周期短就是 OK 的,这个地方,参数 count 是被引用的,现在在 make_combined 函数中,没有人比它的生命周期更长了。
在 Rust 中,输入决定输出,当函数接收参数的时候,不仅接收了数据,还接收了数据附带的生命周期。函数输入的生命周期,决定了函数输出的生命周期。
小结
怎么样,看完 kmdreko 的回答感觉如何,是不是觉得 Rust 没有那么简单?
总结一下,上面主要讲了以下几点:
- 生命周期不会改变你的代码,是你的生命控制生命周期,而不是生命周期在控制你的代码。换言之,生命周期是描述性的,而不是规定性的。
- 一般情况下Rust中的值默认都会分配在栈上,除非我们使用
Box<T>等方法强制将值放在堆上。从编译器的角度看,只要能确定大小,长度固定,原生类型和开发者可以自定义的struct、enum类型,都会分配在栈上。 - 当函数接收参数的时候,接收的不仅是数据,还接收了数据附带的生命周期。一般而言引用值的生命周期只要不比被引用值的生命周期长就可以了。
这两年低代码比较火,这个东西其实十几年前就有,主要就是辅助程序员生成低级代码的,以前基本上大家都写过,只不过现在有人专门拿出来炒它而已。编程其实一向是向更广、更深、更多样化发展的,当有人看到低代码觉得编程越来越简单的时候,认为以后程序员都会失业,都没有用了,那是因为他无知,至少他还没有看到 Rust。
下面附一段作者刚看到 Rust 所有权时写下的一段话,分享给你:
Rust 这个语言很是强大,10 年后它或成为地表最强语言,没有之一,它主要强大在思想上:
- Rust 所有权的本质是数据权责清晰,谁拥有数据,谁担负维护数据一致性的责任。这条规则在数据库实践中是显而易见的真理,但当它被引入到 Rust 语言设计中的时侯,反而引起了程序员的不适应。可以说,Rust 是地表对数据最负责任的编程语言。
- 所有权、移动、不可变引用、可变引用、Copy Trait、Drop Trait 等这些非常规概念,其实拥有着同一个内核,它们都是为了完成同一个 Rust 设计哲学:权责清晰,谁的数据谁负责,不是你的数据你别动。
基础软件设施是不断进化的,以后 Rust 在操作系统、嵌入式、通讯协议等领域应用会越来越普遍。
如果你是一名程序员,有时间一定要学习一下 Rust 这门语言。
该文由 rustpress 编译。

评论