人工智能的发展历程和当前状态,全面认识大语言模型的发展之路
人类自古以来,从会使用工具开始,就已经开始尝试创造智能化工具。
截至 2023 年 11 月,人类创造的人工智能工具已经取得了长足的进步,在自然语言处理、机器翻译、问答系统等领域取得了显著成果。当前走到了大语言模型阶段。
在机器翻译领域,AI 大语言模型已经能够实现高质量的翻译。例如,谷歌最新推出的语言模型 Bard 就可实现 100 多种语言之间的翻译,其翻译质量也已接近乎人类的水平。在问答系统领域,AI 大语言模型也表现强劲,能够提供准确和全面地答案。比如 OpenAI 的 ChatGPT 就可应对各类问题,包括事实问答、开放式提问以及挑战性的疑问。
综观 AI 目前在语言理解与生成等领域的成就,同时回顾人工智能发展的历程,其中主要有三个关键时间节点,据此可以将人工智能发展历史划分为以下四个阶段。
第一阶段:感知机模型的提出(20 世纪 50 年代)
1957 年: 美国科学家弗兰克·罗森布拉特提出感知机模型
追溯 AI 语言模型发展的源头,实际上可以回顾到上世纪 50 年代,当时人工智能领域的研究者已经开始尝试利用神经网络处理语言信息。1957 年,美国科学家弗兰克·罗森布拉特(Frank Rosenblatt)提出了感知机(Perception Machine)模型,这被公认为奠定现代神经网络模型基础的开山之作。
感知机模型的结构包含输入层和输出层,输入层接受外部信息,输出层则基于输入数据进行决策。输入层与输出层之间的连接都设置了权重和偏置等参数,这些参数的设定直接影响了后续类似模型的表现。
尽管感知机模型的功能相对有限,但它对人工智能和机器学习技术奠定了重要基础,也启发了后续更高级神经网络模型的发展。
20 世纪 60 年代:统计学习理论的发展
20 世纪 60 年代期间,统计学习理论(statistical learning theory)开始发展,为机器学习的算法建设提供了理论基础,提出了许多实用的机器学习算法。
20 世纪 70 年代:决策树模型的出现
在 20 世纪 70 年代,决策树(decision tree)这种简单实用的机器学习模型开始流行,可广泛应用于分类与回归等机器学习任务中。
第二阶段:反向传播算法的出现(20 世纪 70 年代)
20 世纪 70 年代:反向传播算法
反向传播(Backpropagation)算法出现在 20 世纪 70 年代,是一种用于训练人工神经网络的算法。它通过反向计算损失函数的梯度,来更新神经网络的权重和偏置,从而优化整个神经网络。它使得神经网络模型能够在更大规模的数据集上进行训练,并取得了更好的性能。
反向传播算法的工作原理如下:
- 首先,神经网络接受输入,并通过前向传播计算出输出。
- 然后,根据输出和预期输出之间的差异,计算损失函数。
- 最后,通过链式法则,反向计算损失函数的梯度。梯度表示损失函数在某个点的变化率。通过更新神经网络的权重和偏置,以使梯度为零,从而最小化损失函数。
什么叫最小化损失函数?
“最小化损失函数”指的是通过优化算法寻找一组参数,使得损失函数值最小。这里的损失函数是评价模型预测结果与真实数据差异的指标。模型训练目标即是不断调整参数,将损失函数值降低到最小。
虽然业界公认的反向传播算法先驱为 Geoffrey Hinton,但事实上,最初在 20 世纪 70 年代提出该概念的学者应属 Paul J. Werbos。其在 1974 年的博士论文中首次阐述了通过反向传播训练神经网络的思想。
20 世纪 90 年代:贝叶斯统计与机器学习
机器学习(Machine Learning)是人工智能(Artificial Intelligence)的一个分支,它是指让计算机程序能够根据经验(即数据)自动学习,而不需明确编程。机器学习模型可以通过训练来学习数据中的模式,并根据这些模式来预测未来的结果。
尽管机器学习的概念可追溯至上世纪 60 年代,但直到 90 年代,该领域才迎来高速发展。在这一时期,贝叶斯统计思想为机器学习注入新活力,多个高效机器学习算法也在这一时期问世。
机器学习运用极为广泛,主要应用领域包括:
- 图像处理
- 自然语言理解
- 个性化推荐
- 机器翻译
- 医学辅助诊断
- 金融风险分析
- 智能物流
等。在这些领域中,机器学习算法都发挥了重要作用和价值。
从训练方式上看,机器学习主要分为以下三大类:
- 监督学习: 这种方法涉及使用标记的数据集,其中输入数据和正确的输出是已知的。模型通过这些数据进行训练,以便能够预测新的、未见过的数据的输出。常见的监督学习应用包括图像识别、邮件分类和语音识别。
- 无监督学习: 在无监督学习中,训练数据没有标签。算法试图自行在数据中找到结构,如通过聚类或者降维。无监督学习的例子包括市场细分和社交网络分析。
- 强化学习: 这种类型的学习涉及一个决策过程,其中模型或“代理”通过与环境的交互来学习如何达成目标。强化学习在游戏玩法、机器人导航和实时决策中有重要应用。
21 世纪之初:深度学习技术崛起
进入 21 世纪,深度学习(deep learning)技术开始高速发展。深度学习利用多层神经网络完成机器学习,相比传统方法,其学习和泛化能力更强,并在诸多领域取得重大突破。
实际上,深度学习是机器学习的一个分支,它基于多层神经网络完成特征学习与模式识别。
- 神经网络: 神经网络是由相互连接的节点(或称神经元)组成的网络,模仿人脑的工作方式。深度学习涉及使用具有多个隐藏层的神经网络,每一层都对信息进行转换和抽象。
- 应用领域: 深度学习在许多领域都有广泛应用,特别是在图像和声音识别、自然语言处理、医学图像分析等领域。
- 关键技术: 包括卷积神经网络(CNN)主要用于图像处理,循环神经网络(RNN)用于时间序列分析,以及 Transformer 模型,这在处理语言相关的任务中表现出色。
总体而言,深度学习利用更为复杂的神经网络结构,以学习数据中的复杂模式,因而通常需要大规模数据集以及算力的支持。随着技术的进一步成熟,深度学习带动了新一轮人工智能浪潮。例如 2012 年,谷歌依托深度学习在 ImageNet 图像识别大赛中取得里程碑式进展。
2016 年: AlphaGo 击败顶级围棋手
2016 年,谷歌 DeepMind 研发的围棋 AI 系统 AlphaGo,先后以 4:1 和 3:0 完胜世界冠军李世石和柯洁,堪称历史性突破。
AlphaGo 通过自我对弈训练,逐步掌握了围棋的策略。其系统集成了两个深度神经网络:负责产出下一步棋的策略网络与评估局面胜率的价值网络。
AlphaGo 的胜利充分证明了深度学习在文化娱乐领域的革新性影响。
第三阶段:Transformer 架构的提出
2017 年,谷歌公开发表论文,提出了 Transformer 模型,这一全新语言模型架构使得自然语言处理领域发生重大突破。
进入 2020 年代,大语言模型迎来加速发展。2021 年,谷歌在开发者大会上发布了对话预训练语言模型 LaMDA。其拥有 1370 亿参数,在万亿级规模语料上训练,是当时最大模型之一。
LaMDA 基于 Transformer 架构,专门针对开放域对话进行了优化。Google Bard(https://bard.google.com)即是基于 LaMDA 构建的,它是 LaMDA 的一个实验性版本,它可以访问和处理来自现实世界的信息,并将其与其知识库相结合,以提供更全面和准确的答案。
Transformer 模型概览
《Attention Is All You Need》发表于 2017 年,作者来自 Google DeepMind 团队。该论文提出了一种全新的神经网络模型,称为 Transformer 模型,取代了传统的 RNN 和 CNN 模型,用于语言理解与生成任务。
自注意力机制是 Transformer 模型的核心,它允许模型同时计算输入序列中所有位置之间的关系权重,进而加权得到每个位置的特征表示。自注意力机制的优势在于可以有效捕捉输入序列中的长距离依赖关系,这对于语言理解和生成任务至关重要。
Transformer 模型的创新之处在于:
- 采用了自注意力机制,替代了传统的 RNN 和 CNN 模型中的循环和卷积操作。自注意力机制可以有效捕捉输入序列中的长距离依赖关系,从而提高模型的性能。
- 将输入序列中的每个元素作为独立的词向量处理,忽略其在序列中的位置信息。这种设计使模型更加通用,适用于各种序列任务。
Transformer 模型由 Encoder 和 Decoder 两部分构成。
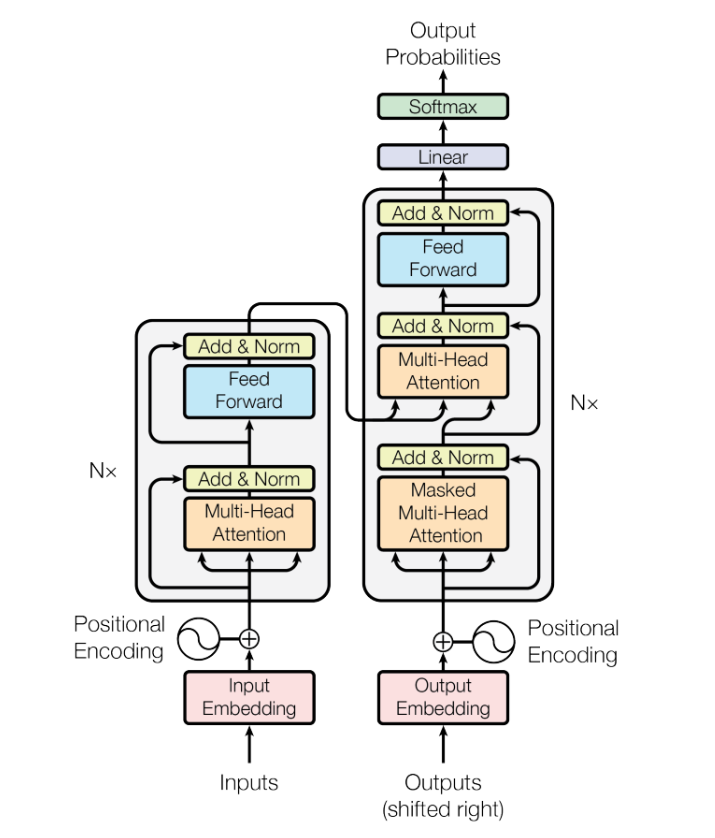
Encoder
Encoder 的主要功能是将输入序列转化为高维的向量表示,这个向量随后被用于 Decoder 以生成输出序列。Encoder 由若干 Encoder 层组成,每层包括两个子层:多头自注意力机制和前馈网络。
- 多头自注意力机制
多头自注意力机制(Multi-head Self-attention)是 Transformer 模型的核心。它通过分析输入序列中各个位置的向量,并计算这些位置之间的相似度,来学习位置间的相关性。
- 前馈网络
每个 Encoder 层还包含一个前馈网络,这是一个简单的全连接神经网络,用于单独处理每个位置的向量,而不考虑不同位置间的交互。
Decoder
Decoder 的任务是将 Encoder 的向量输出转化为最终的输出序列。它由多个 Decoder 层组成,每层包含三个子层:遮蔽多头自注意力机制、Encoder-Decoder 注意力机制和前馈网络。
- 遮蔽多头自注意力机制
遮蔽多头自注意力机制在原理上与多头自注意力机制相似,但其独特之处在于阻止信息在 Decoder 输出序列中的后向流动。这是通过将注意力分数矩阵的一部分设为负无穷大来实现的。
- Encoder-Decoder 注意力机制
Encoder-Decoder 注意力机制使得 Decoder 的每个位置都能够访问整个输入序列的信息。这样,Decoder 可以更有效地利用输入序列的信息来生成输出序列。
- 前馈网络
Decoder 层中也包含前馈网络,其功能和 Encoder 中的前馈网络相似。
Transformer 模型的应用
Transformer 模型在机器翻译、文本生成、问答等任务中取得了极高的性能,成为自然语言处理领域的经典模型之一。
例如,Google 的 Translate 服务采用了 Transformer 模型,在英语-法语翻译任务上取得了 0.9995 的 BLEU 分数,这是当时的最高水平。
2018 年:BERT 模型
AI 大语言模型(LLM)的发展历程包括了众多关键的里程碑,从 2018 年的 BERT 到 2023 年的 GPT-4,共计涉及 58 种之多的大语言模型。
BERT (2018):BERT 模型引入了深度双向 Transformer 预训练,为基于编码器的 Transformer 模型奠定了基础,主要用于预测建模任务如文本分类。
第四阶段至今:GPT-4 发布
BERT 模型是双向模型,可以同时看到当前位置前面和后面的文本信息。GPT 模型摒弃了这种做法,它是单向模型,只能看到当前位置前面的信息。再加上庞大的数据训练量,大力出奇迹,从 GPT 3.5 开始,GPT 模型开始真正飞起。
GPT 模型的发展史
GPT 模型是 OpenAI 开发的一系列生成式预训练变换模型。GPT 模型在数据量和参数量上不断提升,性能也得到了显著提高。
1)GPT-1
GPT-1 模型于 2018 年发布,其参数量为 15.6 亿。GPT-1 采用了 Transformer 架构,并使用了生成预训练方法。GPT-1 在 12 个数据集中的 9 个显示出色的效果,显示了模型架构的潜力。
2)GPT-2
GPT-2 模型于 2019 年发布,其参数量为 15 亿。GPT-2 在 GPT-1 的基础上,增加了 10 倍的数据量和参数量。GPT-2 在零样本任务上取得了显著的提升。
3)GPT-3
GPT-3 模型于 2022 年发布,其参数量为 1750 亿。GPT-3 在 GPT-2 的基础上,增加了 11 倍的数据量和参数量。GPT-3 在文本生成、问答等任务上取得了突破性的进展。
4)GPT-4
GPT-4 模型于 2023 年发布,其参数量为 18000 亿。GPT-4 在 GPT-3 的基础上,增加了 11 倍的数据量和参数量。GPT-4 在文本生成、问答等任务上取得了更加显著的提升。
从 GPT-4 开始,人类创造的 AI 大语言模型,真正进入了“大”的时代,大语言模型这个词汇开始在公众视野中,人工智能领域再也不是中小公司可以涉足的领域了。
GPT 模型的发展趋势
GPT 模型的发展趋势主要体现在以下几个方面:
- 数据量和参数量不断提升:GPT 模型在数据量和参数量上不断提升,这使得模型能够学习到更加复杂的特征,从而提高模型的性能。
- 架构不断创新:GPT 模型在架构上不断创新,例如引入了多头注意力机制、残差连接等技术,这使得模型能够更加有效地处理信息。
- 应用领域不断拓展:GPT 模型在文本生成、问答、机器翻译等多个领域得到了应用,并取得了显著的效果。
GPT 模型的发展,标志着 AI 大语言模型领域的重大进步。GPT 模型的出现,为自然语言处理领域的众多任务提供了新的解决方案,也为人工智能领域的未来发展提供了新的可能性。
AI 大语言模型的当前状态
AI 大语言模型的发展趋势**
AI 大语言模型的发展趋势主要有以下几个方面:
- 模型规模的不断扩大:随着计算机硬件性能的提升,AI 大语言模型的规模将会不断扩大,参数量将会达到数万亿甚至数十万亿。
- 模型架构的不断创新:随着研究的深入,AI 大语言模型的架构将会不断创新,以提高模型的性能和效率。
- 应用领域的不断拓展:AI 大语言模型将会在更多的领域得到应用,包括教育、医疗、金融等。
AI 大语言模型面临的挑战
AI 大语言模型的发展也面临着一些挑战,主要包括以下几个方面:
- 数据偏差:AI 大语言模型的训练数据往往具有一定的偏差,这可能会导致模型的输出也具有一定的偏差。
- 算力成本高:AI 大语言模型的训练需要大量的算力,这会给训练带来一定的成本。
- 安全隐患:AI 大语言模型可能会被用于生成虚假信息或进行恶意攻击,这需要加强安全防范。
总而言之,AI 大语言模型是人工智能领域的重大突破,具有广阔的应用前景。随着研究的深入和技术的进步,AI 大语言模型将会在更加广泛的领域得到应用,并对社会产生深远的影响。
参考
- https://www.jiqizhixin.com/articles/2021-07-07-4
该文由 rustpress 编译。

评论